网络搜索与获取:让 AI 获取最新信息
📝 课程笔记
本课核心知识点整理:
学完你能做什么
🎯 本课目标
- 让 AI 帮你搜索最新的技术文档和解决方案
- 让 AI 读取指定网页的内容并总结要点
- 根据需要选择合适的搜索参数和输出格式
你现在的困境
你可能遇到过这些情况:
- 问 AI 某个库的最新用法,它给的答案是半年前的
- 想让 AI 帮你读一篇英文文档,但它说"我无法访问网页"
- 遇到一个报错,想让 AI 帮你搜一下解决方案,但它只能靠"记忆"回答
AI 模型的知识有截止日期。网络搜索与获取就是给 AI 装上"眼睛",让它能看到最新的互联网信息。
什么时候用这一招
- 查最新的 API 文档或框架版本变化
- 让 AI 读取某个网页(GitHub README、技术博客、官方文档)
- 搜索某个报错信息的解决方案
- 调研一个不熟悉的技术方案
🎒 开始前的准备
- [x] 完成了 快速开始
- [x] 了解 OpenCode 基本操作
⚠️ websearch 需要额外启用
webfetch(获取网页)默认可用,不需要额外配置。
但 websearch(搜索网络)需要满足以下条件之一才能使用:
- 使用 OpenCode Zen 托管模型(自动启用)
- 设置环境变量
OPENCODE_ENABLE_EXA=true - 设置环境变量
OPENCODE_EXPERIMENTAL=true(会同时启用多个实验性功能)
如果你不确定自己能不能用 websearch,直接在 OpenCode 里试一下就知道了。AI 用不了的工具不会出现在它的工具列表里。
核心思路
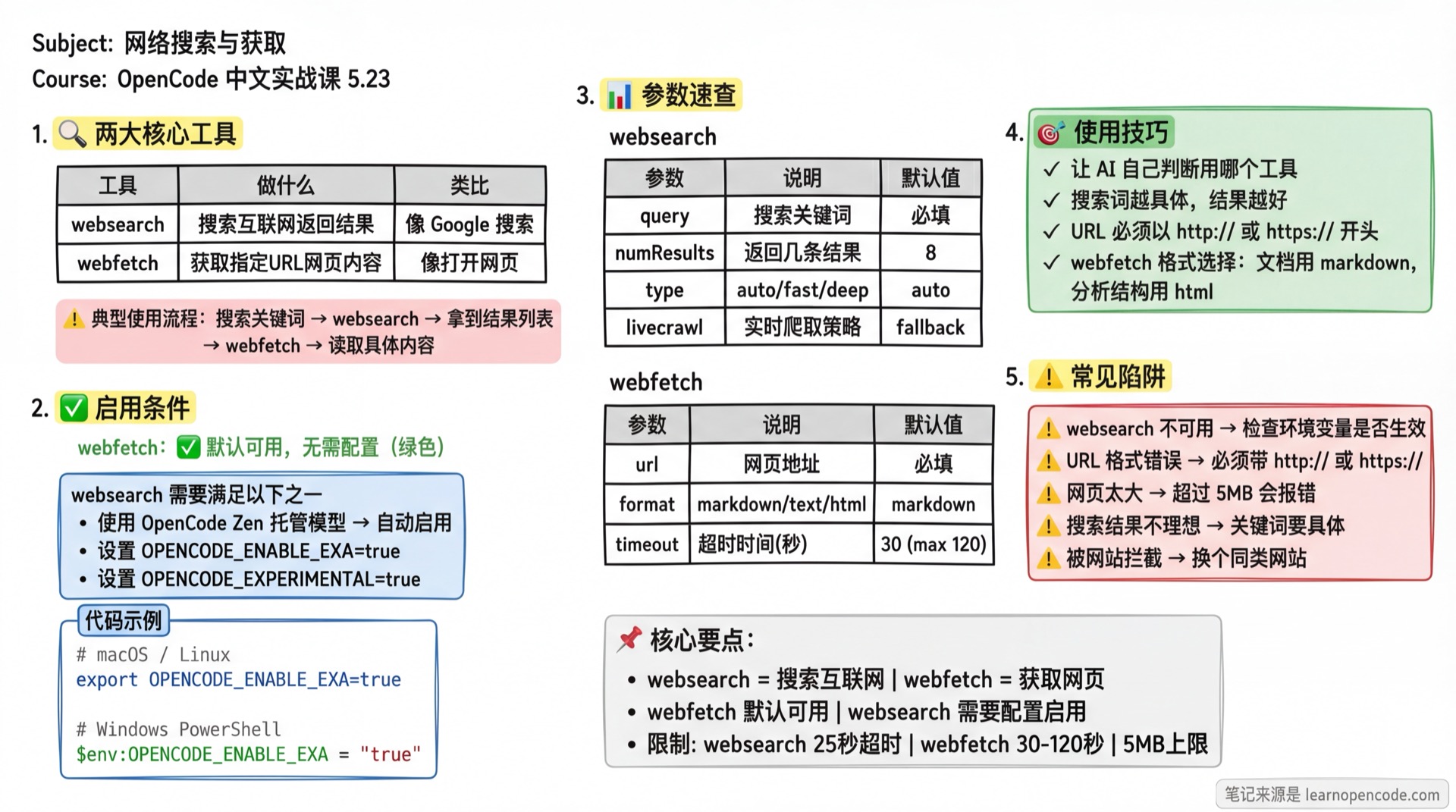
OpenCode 提供了两个网络工具,分工明确:
| 工具 | 做什么 | 类比 |
|---|---|---|
websearch | 搜索互联网,返回结果列表 | 像用 Google 搜索 |
webfetch | 获取指定 URL 的网页内容 | 像在浏览器里打开一个页面 |
典型的使用流程:
你:帮我查一下 React 19 有什么新特性
AI 的操作:
1. websearch "React 19 new features" → 拿到一堆搜索结果
2. webfetch 某个结果的 URL → 读取具体页面内容
3. 整理后回复你你不需要手动告诉 AI 用哪个工具,只要正常提问就行。AI 会自己判断该搜索还是该获取。
跟我做
第 1 步:启用 websearch(非 Zen 用户)
如果你用的是 Zen 托管模型,跳过这步,websearch 已经自动启用了。
其他用户需要设置环境变量:
# macOS / Linux:加到 ~/.bashrc 或 ~/.zshrc
export OPENCODE_ENABLE_EXA=true
# 然后重新打开终端,或执行
source ~/.zshrc# Windows PowerShell
$env:OPENCODE_ENABLE_EXA = "true"你应该看到:重启 OpenCode 后,AI 就能使用 websearch 工具了。
第 2 步:试试网络搜索
打开 OpenCode,直接输入一个需要最新信息的问题:
帮我查一下 Bun 最新版本有什么新特性你应该看到:AI 会调用 websearch 工具,输出类似这样的过程:
⠋ websearch("Bun latest version new features 2026")
Web search: Bun latest version new features 2026
1. Bun v1.x: What's New
URL: https://bun.sh/blog/...
...
2. Bun Release Notes
URL: https://github.com/oven-sh/bun/releases
...然后 AI 会根据搜索结果给你整理一份总结。
第 3 步:试试获取网页内容
如果你已经知道要看哪个页面,可以直接让 AI 去读:
帮我读一下这个页面的内容:https://bun.sh/docs/installation你应该看到:AI 会调用 webfetch 工具,获取页面内容后给你总结。
💡 webfetch 的几种玩法
- "帮我读一下这个 GitHub README"——让 AI 快速了解一个项目
- "帮我翻译这篇英文文档的要点"——AI 读取后直接翻译
- "帮我对比这两个页面的内容"——给两个 URL,AI 分别读取后对比
第 4 步:组合使用
搜索和获取可以串联起来。比如:
我遇到了 "TypeError: Cannot read properties of undefined" 这个错误,
帮我搜一下最新的解决方案,找到最相关的文章后帮我总结要点你应该看到:AI 会先搜索,找到相关文章,然后用 webfetch 读取具体内容,最后给你整理。
websearch 参数速查
你不需要手动传这些参数,AI 会自动选择。但了解一下有助于你在提示词里给出更精确的指令。
| 参数 | 说明 | 默认值 |
|---|---|---|
query | 搜索关键词 | 必填 |
numResults | 返回几条结果 | 8 |
type | 搜索深度 | auto |
livecrawl | 实时爬取:fallback(缓存不可用时爬取)/ preferred(优先实时爬取) | fallback |
contextMaxCharacters | 上下文最大字符数 | 10000(Exa API 默认) |
搜索深度
| 类型 | 说明 | 适合场景 |
|---|---|---|
auto | 平衡模式(默认) | 大多数情况 |
fast | 快速返回 | 简单问题,要速度 |
deep | 深度搜索 | 复杂问题,要全面 |
💡 怎么影响搜索深度?
你可以在提示词里暗示,比如:
- "快速查一下"——AI 可能选
fast - "帮我深入调研一下"——AI 可能选
deep
webfetch 参数速查
| 参数 | 说明 | 默认值 |
|---|---|---|
url | 要获取的网页地址 | 必填 |
format | 输出格式 | markdown |
timeout | 超时时间(秒) | 30(最大 120) |
输出格式怎么选
| 格式 | 说明 | 适合场景 |
|---|---|---|
markdown | 转成 Markdown(默认) | 文档、博客、README |
text | 纯文本 | 只要文字内容,不要格式 |
html | 原始 HTML | 需要分析页面结构 |
大多数情况用默认的 markdown 就够了。AI 会自动把 HTML 页面转成结构清晰的 Markdown。
检查点 ✅
试着回答这几个问题:
- [ ] websearch 和 webfetch 分别做什么?
- [ ] 非 Zen 用户怎么启用 websearch?
- [ ] webfetch 支持哪三种输出格式?
点击查看答案
websearch搜索互联网返回结果列表,webfetch获取指定 URL 的网页内容- 设置环境变量
OPENCODE_ENABLE_EXA=true(或OPENCODE_EXPERIMENTAL=true) markdown(默认)、text、html
踩坑提醒
1. websearch 不可用
如果 AI 没有使用 websearch,可能是没启用。
| 你的情况 | 解决方案 |
|---|---|
| 用 Zen 托管模型 | 应该自动可用,检查网络连接 |
| 用自己的 API Key | 设置 OPENCODE_ENABLE_EXA=true 后重启 |
| 设了环境变量还是不行 | 确认变量生效:echo $OPENCODE_ENABLE_EXA |
2. URL 格式错误
❌ 省略协议头
帮我读一下 example.com/page✅ 给完整 URL
帮我读一下 https://example.com/pagewebfetch 要求 URL 必须以 http:// 或 https:// 开头。
3. 网页太大
webfetch 有 5MB 的大小限制。如果目标页面太大(比如一个巨大的 PDF),会报错 Response too large。
遇到这种情况,试试让 AI 获取更精确的页面,而不是整个大文件。
4. 搜索结果不理想
❌ 太模糊
帮我搜一下 React✅ 具体一点
帮我搜一下 React 19 useOptimistic hook 的用法和示例搜索关键词越具体,结果越好。
5. 被网站拦截
有些网站会拦截自动化请求(比如 Cloudflare 防护)。OpenCode 检测到 Cloudflare 拦截时,会自动用诚实的 User-Agent 重试一次,但不是每次都能成功。
遇到 403 错误,可以试试:
- 换一个同类网站的 URL
- 让 AI 搜索同样的内容,从其他来源获取
本课小结
| 工具 | 做什么 | 默认可用 |
|---|---|---|
webfetch | 获取指定网页内容 | ✅ 是 |
websearch | 搜索互联网 | ⚠️ 需要 Zen 或设置环境变量 |
记住这几个限制:
- websearch 超时:25 秒
- webfetch 超时:30 秒(默认),最大 120 秒
- webfetch 大小限制:5MB
日常使用不需要记参数,正常提问就行。AI 会自己判断该搜索还是该获取,自己选择合适的参数。
下一课预告
下一课我们学习 CLI 自动化。
你会学到:
- 在脚本里调用 OpenCode,无需人工干预
- 启动远程服务器,让团队共享 AI 会话
- 把 OpenCode 嵌入 CI/CD 流水线
附录:源码参考
点击展开查看源码位置
更新时间:2026-02-14
| 功能 | 文件路径 | 行号 |
|---|---|---|
| websearch 工具定义 | src/tool/websearch.ts | 40-150 |
| websearch 参数 Schema | src/tool/websearch.ts | 45-64 |
| webfetch 工具定义 | src/tool/webfetch.ts | 12-166 |
| webfetch 参数 Schema | src/tool/webfetch.ts | 14-21 |
| webfetch 大小和超时限制 | src/tool/webfetch.ts | 8-10 |
| websearch/codesearch 启用条件 | src/tool/registry.ts | 137-139 |
| OPENCODE_ENABLE_EXA 标志 | src/flag/flag.ts | 44-45 |
| Cloudflare 403 重试逻辑 | src/tool/webfetch.ts | 68-72 |
| HTML 转 Markdown | src/tool/webfetch.ts | 200-210 |
关键常量:
API_CONFIG.BASE_URL = "https://mcp.exa.ai"— Exa 搜索 API 地址API_CONFIG.DEFAULT_NUM_RESULTS = 8— 默认搜索结果数MAX_RESPONSE_SIZE = 5 * 1024 * 1024— webfetch 最大响应 5MBDEFAULT_TIMEOUT = 30 * 1000— webfetch 默认超时 30 秒MAX_TIMEOUT = 120 * 1000— webfetch 最大超时 120 秒
关键函数:
abortAfterAny(timeout, signal)— 超时控制(websearch 25 秒,webfetch 可配置)convertHTMLToMarkdown(html)— 用 Turndown 将 HTML 转为 MarkdownextractTextFromHTML(html)— 用 HTMLRewriter 提取纯文本
启用条件逻辑(registry.ts L137-139):
websearch/codesearch 可用条件:
model.providerID === "opencode"(Zen 用户)
OR Flag.OPENCODE_ENABLE_EXA === trueOPENCODE_ENABLE_EXA 的触发方式(flag.ts L44-45):
OPENCODE_ENABLE_EXA=trueOPENCODE_EXPERIMENTAL=true(启用所有实验性功能)OPENCODE_EXPERIMENTAL_EXA=true