5.20 上下文压缩
📝 课程笔记
本课核心知识点整理:
当对话太长时,OpenCode 会自动压缩历史消息,腾出空间继续对话。
学完你能做什么
- 理解什么是上下文压缩及其必要性
- 看懂 TUI 上的 "Context X% used" 到底代表什么
- 掌握
/compact命令的使用时机和效果 - 配置自动压缩行为,控制何时触发压缩
- 自定义模型的上下文窗口大小
你现在的困境
- 对话进行到一半,突然报错 "context overflow"
- 不知道 TUI 右侧的 "Context 85% used" 是怎么算出来的
- 想手动清理历史消息,但怕丢失重要上下文
- 同样的模型,为什么别人能用更长的对话?
什么时候用这一招
- 当你需要:长时间 debug 或重构,对话积累了大量历史记录
- 而且不想:因为上下文超限而被迫重启对话
- 模型报错:
Error: Request too large for context window时
核心思路
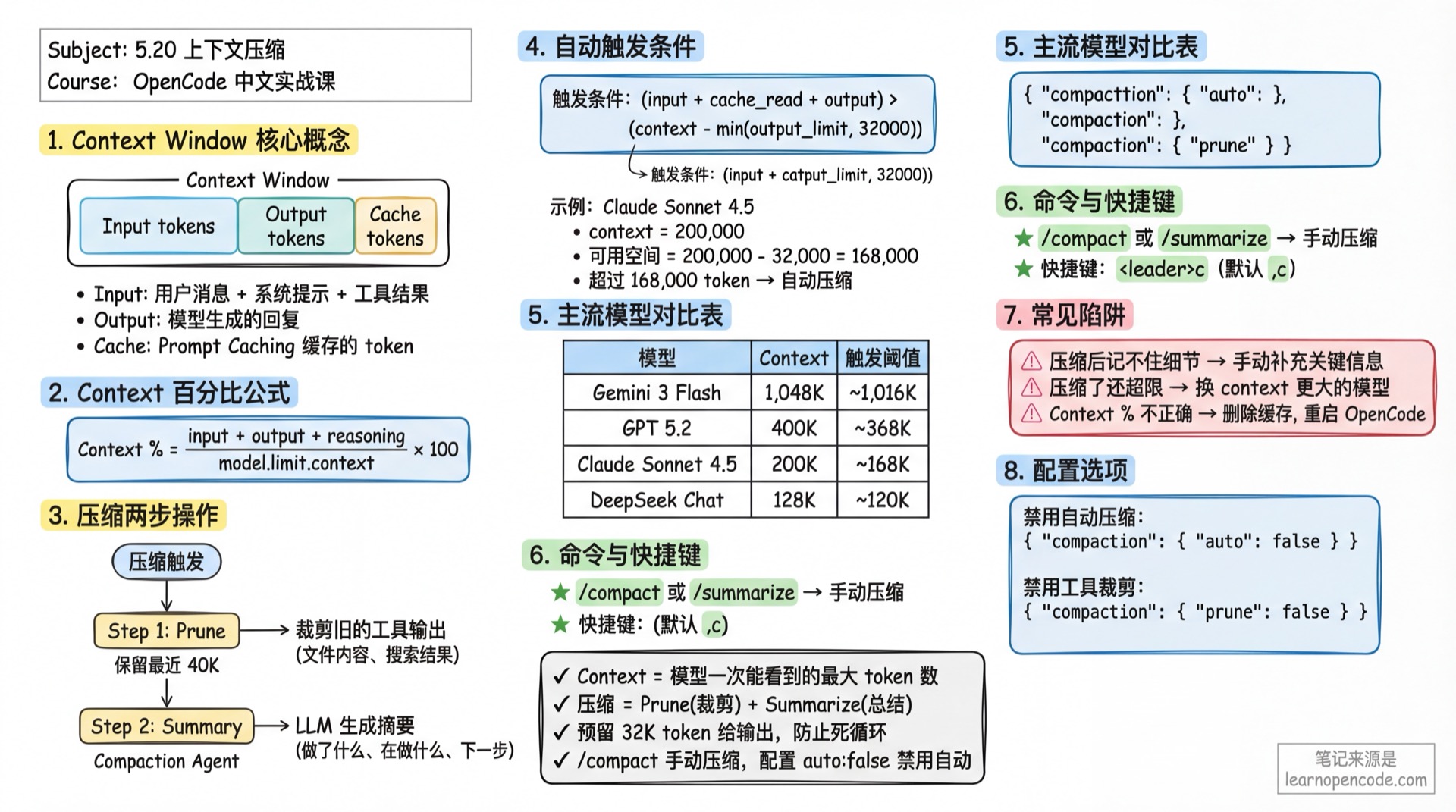
什么是 Context Window?
每个 LLM 模型都有一个上下文窗口(Context Window),限制了模型一次能"看到"的最大 token 数量。超过这个限制,模型就无法处理新的请求。
核心概念:
- Context: 上下文窗口总大小
- Input tokens: 发送给模型的文本(用户消息 + 系统提示 + 工具调用结果)
- Output tokens: 模型生成的回复
- Cache tokens: 使用 Prompt Caching 时缓存的 token
压缩做了什么?
OpenCode 的压缩机制包含两个动作:
Prune(裁剪): 自动清除旧的工具调用输出
- 保留最近 40,000 tokens 的工具输出
- 清除更早的工具输出(如文件内容、搜索结果)
- 避免删除 skill 类工具的输出(通常包含重要状态)
Summarize(总结): 用 LLM 生成摘要
- 将历史对话发送给专门的 compaction agent
- 生成一份详细摘要,包含:做了什么、在做什么、下一步计划
- 用摘要替换原始历史消息,大幅减少 token 占用
原理深度解析
Context 百分比如何计算?
TUI 右侧显示的 "Context X% used" 计算公式:
Context 百分比 = (input + output + reasoning + cache.read + cache.write) / model.limit.context * 100包含的 token 类型:
input: 输入给模型的 tokenoutput: 模型输出的 tokenreasoning: 推理模型的思考过程(如 Claude Thinking)cache.read: 从缓存读取的 tokencache.write: 写入缓存的 token
自动压缩什么时候触发?
核心判断函数(源码位置:src/session/compaction.ts:32-48):
触发条件: token_count >= (input_limit - reserved)
其中 reserved = min(20000, model_max_output)公式解读:
- 计算已使用的 token 总量:
input + output + cache.read + cache.write - 计算预留空间(reserved):默认取
min(20,000, 模型最大输出) - 计算可用空间:
input_limit - reserved - 当已使用量 >= 可用空间时,触发自动压缩
示例计算:
- 模型:Claude Sonnet 4.5(context = 200,000, input = 200,000, output = 64,000)
- 预留空间 = min(20,000, 64,000) = 20,000
- 可用空间 = 200,000 - 20,000 = 180,000
- 当
token_count >= 180,000时触发压缩
为什么需要 reserve token buffer?(v1.1.57 改进)
- 确保 input window 有足够空间进行压缩操作
- 压缩过程本身需要发送摘要请求,需要预留空间
- 压缩更加可靠,减少"压缩失败"的情况
压缩流程详解
第 1 步:Prune 工具输出
// 保留最近 40K tokens 的工具输出
PRUNE_PROTECT = 40_000
PRUNE_MINIMUM = 20_000- 从后往前遍历消息
- 累积工具输出 token,直到达到 40,000
- 超出部分的工具输出标记为
compacted - 如果清理量 > 20,000,才真正执行(避免微不足道的清理)
第 2 步:调用 Compaction Agent
- 创建一个隐藏的 agent(名称:
compaction) - 禁用所有工具权限(
PermissionNext.fromConfig({ "*": "deny" })) - 发送总结 prompt:
"Provide a detailed prompt for continuing our conversation above. Focus on information that would be helpful for continuing the conversation, including what we did, what we're doing, which files we're working on, and what we're going to do next considering new session will not have access to our conversation."
第 3 步:生成摘要并标记压缩点
- 生成的摘要会被标记为
summary: true - 在用户消息中插入
compaction标记,记录压缩点 - 关键区别:
- 用户翻页查看:仍能看到完整历史(数据库未删除)
- 发送给模型:只发送压缩点之后的上下文(节省 token)
主流模型上下文窗口
数据来源
OpenCode 从 https://models.dev/api.json 远程获取最新的模型数据(源码:src/provider/models.ts),每次启动时会更新本地缓存。
常用模型列表
| 模型 | Provider | Context | Output | 触发阈值* |
|---|---|---|---|---|
| Claude Sonnet 4.5 | Anthropic | 200,000 | 64,000 | ~168,000 |
| Claude Opus 4.5 | Anthropic | 200,000 | 64,000 | ~168,000 |
| Gemini 3 Pro | 1,000,000 | 64,000 | ~968,000 | |
| Gemini 3 Flash | 1,048,576 | 65,536 | ~1,016,536 | |
| GPT 5.2 Pro | OpenAI | 400,000 | 128,000 | ~368,000 |
| GPT 5.2 | OpenAI | 400,000 | 128,000 | ~368,000 |
| GLM 4.7 | ZhipuAI | 204,800 | 131,072 | ~172,728 |
| DeepSeek Chat | DeepSeek | 128,000 | 8,192 | ~119,808 |
*触发阈值 = context - min(output, 32,000),仅供参考,实际值以 models.dev 为准
关键发现:
- Gemini 3 Flash 有最大的上下文窗口(~1M),适合超长文档分析
- DeepSeek Chat 的上下文较小(128K),更容易触发压缩
- GPT 5.2 系列的输出限制很大(128K),预留空间充足
跟我做
第 1 步:查看当前 Context 用量
在 TUI 右侧边栏,找到 Context 区域:
Context
145,234 tokens 73% used这表示当前对话使用了 145,234 个 token,占模型上下文窗口的 73%。
你应该看到:
- 如果你使用的是 GPT 5.2(context = 400,000),显示的百分比适中
- 如果使用的是 Gemini 3 Flash(context = 1,048,576),显示的百分比会很低
第 2 步:手动触发压缩
当你觉得对话太长,想手动压缩时,可以使用以下方式:
方式 1:TUI 命令 在输入框中输入:
/compact或别名:
/summarize方式 2:快捷键 按 <leader>c(默认是 ,c)
你应该看到:
- 输入框会出现
Compacting...提示 - 模型会生成一份详细摘要
- 压缩完成后,对话历史会被替换为摘要内容
第 3 步:观察压缩效果
压缩完成后,查看 Context 百分比:
Context
45,678 tokens 23% used对比压缩前的 73%,你会发现 token 使用量大幅下降。
你应该看到:
- 旧的工具调用结果被清除(如文件读取内容)
- 保留了一份详细的对话摘要
- 继续对话时,模型会基于摘要继续工作
重要澄清(容易误解):
| 场景 | 能否看到原始对话 |
|---|---|
| 用户翻页查看 | ✅ 能(数据库未删除) |
| 发送给模型 | ❌ 不能(只发送压缩点之后的消息) |
压缩不删除数据库中的历史消息,只影响发送给模型的上下文。用户随时可以往上翻页查看完整历史。
检查点 ✅
- [ ] 理解 Context 百分比的计算公式
- [ ] 能手动触发
/compact命令 - [ ] 压缩后 Context 百分比明显下降
- [ ] 模型能基于摘要继续对话
高级配置
配置文件位置
OpenCode 支持多层级配置,按优先级从高到低:
| 位置 | 优先级 | 说明 |
|---|---|---|
./opencode.json | 高 | 项目级配置(推荐用于项目特定设置) |
~/.config/opencode/opencode.json | 低 | 全局配置(推荐用于个人偏好) |
OPENCODE_CONFIG 环境变量 | 最高 | 自定义配置文件路径 |
OPENCODE_CONFIG_DIR 环境变量 | - | 自定义配置目录 |
配置预留空间(v1.1.57 新增)
压缩触发时会预留一定的 token 空间,确保压缩操作本身能顺利进行:
opencode.json
{
"compaction": {
"reserved": 30000
}
}参数说明:
- 默认值:
min(20000, 模型最大输出) - 作用:控制何时触发压缩(提前量)
- 场景:如果压缩经常失败,可以增大此值
禁用自动压缩
如果你不想让 OpenCode 自动压缩,可以在配置文件中设置:
opencode.json
{
"compaction": {
"auto": false
}
}或在命令行中:
OPENCODE_DISABLE_AUTOCOMPACT=true opencode禁用工具输出裁剪
Prune 功能会自动清除旧的工具输出。如果你想保留所有工具输出:
opencode.json
{
"compaction": {
"prune": false
}
}或在命令行中:
OPENCODE_DISABLE_PRUNE=true opencode自定义模型上下文限制
如果你想修改某个模型的 context 或 output 限制(例如,想提前触发压缩):
opencode.json
{
"provider": {
"openai": {
"models": {
"gpt-5.2": {
"limit": {
"context": 100000,
"output": 10000
}
}
}
}
}
}示例场景:
- 原始 GPT 5.2: context = 400,000,触发阈值 ~368,000
- 自定义后: context = 100,000,触发阈值 ~90,000
- 效果:在对话更早期就触发压缩,避免超限
为什么这样做?
- 某些模型在高 context 使用率时性能下降
- 你希望更早压缩,保留更多生成空间
- 节省 API 成本(更少的 token 输入)
踩坑提醒
| 现象 | 原因 | 解决 |
|---|---|---|
| 压缩后模型记不住细节 | 压缩摘要丢失了关键信息 | 手动补充关键信息,或重启对话 |
| 压缩了还是超限 | 模型输出太长,超过预留空间 | 减少 max_tokens,或换 context 更大的模型 |
| Context 百分比显示不正确 | models.dev 数据过期,本地缓存未更新 | 删除缓存,重启 OpenCode |
| 不想用压缩 | 禁用了自动压缩,但还是触发 | 检查环境变量 OPENCODE_DISABLE_AUTOCOMPACT 是否生效 |
压缩摘要质量不高
Compaction Agent 使用的 prompt 是固定的。如果你发现压缩质量不好:
- 检查原始对话质量:过于分散的对话难以总结
- 手动补充摘要:压缩后手动输入 "总结补充:..."
- 使用不同的模型:compaction agent 默认使用当前对话的模型
压缩后忘记上下文
压缩后的摘要虽然详细,但无法包含所有细节。如果你发现模型忘记重要信息:
- 重启对话:从头开始,但会丢失所有历史
- 手动补充:在压缩后输入关键信息的总结
- 调整摘要质量:通过插件覆盖 compaction prompt(高级用法)
本课小结
你学会了:
- Context 百分比计算公式:
(input + output + reasoning + cache.read + cache.write) / model.limit.context * 100 - 自动压缩触发条件:
token_count >= (input_limit - reserved),其中 reserved 默认 20,000 - 压缩的两步操作:Prune(清除旧工具输出)+ Summarize(生成摘要)
- 主流模型的上下文限制:从 128K(DeepSeek Chat)到 1M(Gemini 3 Flash)
- 控制压缩行为:通过
compaction.auto、compaction.prune和compaction.reserved配置 - 自定义模型限制:在
provider.models中覆盖limit.context和limit.output - v1.1.57 改进:reserve token buffer 确保压缩更可靠
下一课预告
下一课我们学习 5.21 思考深度配置。
你会学到:
- 为单个模型设置思考预算
- 用变体机制控制推理深度
- 用 Ctrl+T 快速切换
附录:源码参考
点击展开查看源码位置
更新时间:2026-02-14(v1.1.57)
如果你对压缩机制的实现感兴趣,可以查看源码:
| 功能 | 文件路径 | 行号 |
|---|---|---|
| 压缩核心逻辑 | src/session/compaction.ts | 全文件 |
| 自动触发判断(含 reserved) | src/session/compaction.ts | 32-48 |
| Prune 裁剪逻辑 | src/session/compaction.ts | 58-90 |
| Context 百分比计算 | src/cli/cmd/tui/routes/session/sidebar.tsx | 51-61 |
| 压缩配置项 | src/config/config.ts | 927-932 |
| 模型 limit Schema | src/provider/provider.ts | 498-501 |
| 用户自定义 limit | src/provider/provider.ts | 722-724 |
| Compaction Agent | src/agent/agent.ts | 122-136 |
| Compaction Prompt | src/agent/prompt/compaction.txt | 全文件 |
| TUI 显示消息(不过滤) | src/session/index.ts | 492-506 |
| 发送给模型时过滤 | src/session/prompt.ts | 298 |
| filterCompacted 实现 | src/session/message-v2.ts | 794-809 |
关键常量:
COMPACTION_BUFFER = 20,000:默认预留空间(v1.1.57 新增)PRUNE_PROTECT = 40,000:保护最近 40K tokens 的工具输出PRUNE_MINIMUM = 20,000:最小裁剪阈值